On this page
Every organisation has a knowledge problem.
A senior engineer leaves and takes fifteen years of context with them. A student sits in an exam unable to recall which section of the textbook had the relevant detail. A new team member spends months asking questions that nobody has time to answer properly.
The information exists. It is sitting in PDFs, runbooks, lecture notes, configuration guides, and post-incident reviews. The problem is that it is not queryable. You cannot reason across it. You cannot ask it a question and get a response that connects three different documents, flags the relevant caveats, and explains the reasoning behind the answer.
This guide builds a solution to that problem. We take a 32 billion parameter AI language model and train it on your specific documents. That could be a company's internal knowledge base, a university course pack, a technical reference library, or a set of operational procedures. The trained model runs entirely on your own machine. Nothing leaves your hardware. There are no subscription costs or per-query fees. The knowledge base grows as your documents grow.
To demonstrate this concretely, I will use a real example throughout: training a model to be an expert on Cisco Nexus 9000 networking equipment using Cisco's own documentation. The process is identical regardless of your domain. Only the documents change.
What We Are Building
Before touching a terminal, it helps to understand what the finished system looks like and what each component does.
The fine-tuned model is the AI that has been trained on your documents. It knows your domain's vocabulary, understands how your material reasons through problems, and answers questions in a way that reflects your specific knowledge base rather than generic internet information.
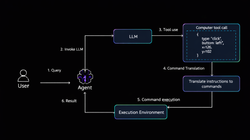
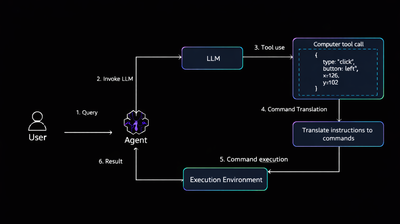
The RAG pipeline (Retrieval-Augmented Generation, more on this shortly) is a system that searches your indexed documents at query time and feeds the most relevant passages to the model alongside your question. Think of it as giving the model an open-book exam rather than asking it to recall everything from memory.
The knowledge base is a searchable database of your documents, stored locally on your machine. It is what the RAG pipeline searches.
Together, these three things give you a private AI assistant that answers questions by reasoning across your own material, cites where it found the information, and stays current as your documents are updated.
Concepts Worth Understanding First
You do not need to understand these deeply to follow the guide. But knowing what each term means will help you understand why each step exists.
Fine-Tuning: Teaching the Model Your Domain
Large language models like the one we use here are pre-trained on enormous amounts of text from the internet. They understand language, can reason through problems, and know a great deal about the general world. What they do not know is anything specific to your organisation, your course material, or your internal systems.
Fine-tuning runs additional training on a small, focused dataset derived from your documents. The model does not forget its general intelligence. It gains a specialisation layer on top of it. After fine-tuning, when you ask it a question that appears in your material, it answers the way your material would answer it, using your terminology and your reasoning patterns.
LoRA: How Fine-Tuning Becomes Practical on Everyday Hardware
A 32 billion parameter model contains 32 billion individual numbers that together represent everything the model has learned. Re-training all of them would require data centre hardware and months of time.
LoRA (Low-Rank Adaptation) is a technique that sidesteps this. Instead of modifying the full model, it inserts small additional matrices into specific layers. These matrices contain far fewer numbers than the full model, and only they get updated during training. The result is that fine-tuning a 32 billion parameter model becomes possible on a laptop with enough memory.
Think of it like a specialist overlay: the underlying model stays intact, and the LoRA adapter on top of it steers the model's responses toward your domain.
RAG: Giving the Model a Library to Reference
A model's knowledge is fixed at the time it was trained. If you add a new document to your knowledge base, the model does not automatically know about it until you retrain.
RAG solves this. When you ask a question, the system first searches your document database for the passages most relevant to your question, then sends those passages alongside your question to the model. The model answers using both its trained knowledge and the fresh context it just received.
This means the model always has access to the actual source material. For a company, it is how you keep the model current as procedures are updated. For a student, it ensures answers reference the actual textbook rather than a vague approximation of it.
GGUF: The Format That Makes It All Run
Once the model is trained, it needs to be converted into a format that the local model runtime can read. GGUF is that format. It is a single file containing the model weights, vocabulary, and configuration, all bundled together.
During conversion, the weights are also quantized: compressed from 32-bit floating point numbers down to 4-bit integers. This reduces a 65GB model to approximately 20GB with minimal quality loss, making it practical to store and run on a laptop.
What Runs Everything: Ollama
Ollama is the software that serves AI models on your local machine. It handles loading the model into memory, receiving your questions, running the model, and returning the answers. Once a model is registered with Ollama, you can talk to it through a simple interface or, as we do in this guide, through code that builds more sophisticated query pipelines on top of it.
The One-Command Setup
Everything described in this guide is automated in a single setup package available on GitHub. The PDF extraction, the training data generation, the fine-tuning, the GGUF conversion, the model deployment, and the RAG pipeline are all handled for you.
git clone git@github.com:aramidetosin/cisco-nexus-llm.git
cd cisco-nexus-llm
chmod +x cisco_nexus_finetune_pipeline.sh
./cisco_nexus_finetune_pipeline.sh
That is the complete sequence to go from nothing to a deployed expert model. The script checks that your environment is ready before starting each stage, saves progress so it can resume if interrupted, and produces clear output showing what is happening and whether each step succeeded.
The rest of this guide explains what the script does at each stage, why it does it, and what you should see. Understanding the process means you can adapt it to your own knowledge base, troubleshoot if something goes wrong, and extend it as your needs grow.