On this page
Abstract
This blog post presents a standards-based framework for designing data center networks that support artificial intelligence (AI) and machine learning (ML) workloads using Ethernet VPN (EVPN) and Virtual Extensible LAN (VXLAN) technologies. We outline the key network requirements of AI/ML clusters – including high throughput, low latency, and scalability – and show how an EVPN-VXLAN fabric can meet these demands with a standardized, interoperable approach. The paper provides an overview of EVPN-VXLAN mechanisms based on the latest IETF standards and RFCs, and details best practices for building a leaf-spine IP fabric that enables multi-tenancy, efficient east-west traffic handling, and lossless data delivery for distributed AI training. Architectural considerations such as routing design, congestion control (for RDMA over Converged Ethernet), and network automation are discussed. We conclude with recommendations and emerging trends for future-proof AI network designs leveraging EVPN-VXLAN.
Introduction
Artificial intelligence (AI) and machine learning (ML) workloads are becoming increasingly commonplace in modern data centers. These workloads – such as training large neural networks or running inference on massive datasets – impose stringent demands on the network infrastructure. Unlike traditional enterprise applications, AI/ML clusters generate extremely high east-west traffic (server-to-server) and require near line-rate throughput with minimal latency and packet loss. For example, a distributed training job across many GPU servers may exchange terabytes of data during an all-reduce operation, saturating links and stressing network buffers. The network must therefore provide maximum throughput, minimal latency, and minimal interference for AI traffic flows. Additionally, consistency and scale are crucial – clusters can range from a few nodes to thousands of nodes, and network architectures must scale out accordingly while isolating different teams or tenants running concurrent AI workloads.
To meet these challenges, cloud and data center networks are evolving beyond traditional Layer-2 VLAN or Layer-3 only designs. A popular modern approach is to build an IP fabric (often in a leaf-spine Clos topology) with an overlay that provides Layer-2 extension and tenant segmentation as needed. Ethernet VPN (EVPN) combined with VXLAN encapsulation has emerged as a leading standards-based solution for such scenarios. EVPN-VXLAN offers the flexibility of Layer-2 adjacency over a routed fabric, enabling large-scale virtual networks on top of the physical infrastructure. At the same time, it uses a control-plane (BGP EVPN) to disseminate network reachability information, avoiding the flooding and scaling issues of older overlay approaches. This paper explores how an EVPN-VXLAN fabric can be designed specifically to support AI/ML workloads, leveraging the latest standards (IETF RFCs) and industry best practices. We discuss the key technical components of EVPN-VXLAN, then outline design considerations – such as multitenancy, routing efficiency, congestion management for RDMA traffic, and high availability – for AI-centric networks. Finally, we present recommendations and highlight emerging trends influencing next-generation AI networking.
EVPN-VXLAN Overview and Standards
VXLAN was initially introduced as an overlay mechanism to stretch Layer-2 networks over a Layer-3 infrastructure, and is documented in RFC 7348 (2014). The original VXLAN approach relied on flood-and-learn behavior, using multicast or head-end replication to handle unknown MAC address discovery and broadcast traffic (as described in RFC 7348). While this allowed virtual Layer-2 networks (identified by a 24-bit VNI) to be created over IP networks, the lack of a control plane in early VXLAN meant limited scalability and potential efficiency issues. For example, the flood-and-learn VXLAN model required underlying network support for multicast and could lead to excessive broadcast traffic in large deployments.
To overcome these limitations, the networking industry adopted BGP EVPN as the control-plane for VXLAN overlays. EVPN was originally defined for MPLS-based VPNs (RFC 7432, 2015) as a way to carry Layer-2 and Layer-3 VPN information in BGP and support features like multipath and redundancy. Subsequently, RFC 8365 (2018) extended EVPN for network virtualization overlays, specifying how EVPN can operate with VXLAN and similar encapsulations in data center networks. In an EVPN-VXLAN fabric, each switch (typically a top-of-rack leaf) that participates in the overlay runs BGP and advertises tenant MAC addresses and IP prefixes using EVPN route updates. This eliminates the need for data-plane flooding for MAC learning — instead, endpoints (e.g., servers or VMs) are learned locally and distributed to all relevant fabric nodes through BGP EVPN. The result is a highly scalable solution where Layer-2 segments can be extended across the data center over a Layer-3 IP underlay, with efficient control of broadcast, unknown unicast, and multicast (BUM) traffic and optimized unicast forwarding.
Several IETF standards govern this EVPN-VXLAN framework. Key among them, RFC 7432 defines the foundational EVPN BGP routes and attributes (for MPLS networks originally), including route types for MAC/IP advertisement, Ethernet segment discovery, etc. RFC 8365 (“Ethernet VPN (EVPN) as a Network Virtualization Overlay”) defines how those EVPN route types are used with VXLAN and other encapsulations, and introduces enhancements for split-horizon filtering (to prevent loops on multi-homed links) and mass-withdraw (to efficiently withdraw routes on link failure) in an NVO3 context. Furthermore, EVPN supports integrated routing and bridging (IRB), which is critical for Layer-3 communications in the overlay: RFC 9135 (2021) specifies how EVPN is used for inter-subnet routing within the fabric, providing options for symmetric and asymmetric IRB models. In practice, modern data center deployments use symmetric IRB with EVPN-VXLAN – meaning each leaf acts as the default gateway for its local hosts and routes traffic to remote subnets via VXLAN, using EVPN route type-5 (IP prefix) or type-2 (MAC/IP) advertisements for cross-subnet forwarding. This ensures optimal East-West routing without hair-pinning traffic through a centralized router.
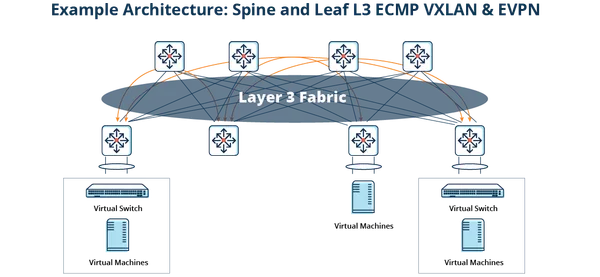
A standard EVPN-VXLAN based network fabric thus consists of an IP underlay (often running eBGP/IBGP or an IGP for basic IP reachability) and an overlay where BGP EVPN sessions exchange tenant network information. This approach is vendor-neutral and standardized, with multi-vendor interoperability widely demonstrated. By adhering to these RFC standards (and relevant IEEE standards for data center bridging, discussed later), network architects can build fabrics that are future-proof and not locked into proprietary protocols.
Network Requirements for AI/ML Workloads
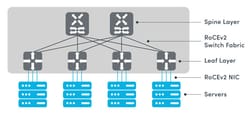
AI/ML workloads introduce unique network requirements that influence the design of the EVPN-VXLAN fabric. First and foremost is bandwidth and scalability: AI training clusters interconnect dozens or hundreds of servers (each with multiple GPUs or specialized AI accelerators) and exchange large volumes of data, often saturating 25 GbE/50 GbE/100 GbE links today and moving towards 200 GbE/400 GbE in the near future. The network must support non-blocking or low-oversubscription pathways so that East-West traffic can scale linearly as more nodes are added. A leaf-spine Clos topology is well-suited here, as it provides predictable scaling – new spine switches increase fabric capacity, and new leaf switches add rack capacity without impacting existing connections. EVPN-VXLAN fits naturally with this Clos design, since it allows an arbitrary mesh of tunnels between leaf switches (VTEPs) and leverages equal-cost multi-path (ECMP) load balancing across the IP underlay. This ensures that large flows can utilize multiple links in parallel and that no single path becomes a bottleneck. Advanced hashing or flow-distribution techniques (e.g., flowlet-based load balancing) may be employed to avoid out-of-order packets while maximizing utilization of available links.