Abstract
Remote Direct Memory Access over Converged Ethernet version 2 (RoCEv2) is a high-performance networking protocol that brings the low-latency, high-throughput benefits of RDMA to standard Ethernet networks. RoCEv2 extends RDMA’s capabilities over routable Layer 3 (IP) networks, enabling scalable deployments across data center fabrics. This paper provides a technical overview of RoCEv2, including its architecture, packet structure, and requirements for lossless Ethernet operation. Key findings indicate that RoCEv2 can approach InfiniBand-level performance (single-digit microsecond latency and line-rate throughput) when configured with proper congestion control and priority flow control. Industry adoption has grown rapidly – hyperscale cloud and AI infrastructure (e.g. Meta’s GPU clusters) leverage RoCEv2 for distributed training, while enterprise solutions use it for accelerating storage and database systems. We discuss real-world case studies (Meta AI superclusters, Azure Stack HCI, Oracle Cloud trading systems, and NVMe-oF storage) that demonstrate RoCEv2’s impact. Comparative analysis with InfiniBand and iWARP reveals trade-offs in performance versus deployment complexity. We also outline best practices for deploying RoCEv2 (lossless fabric configuration, QoS tuning, congestion management, and monitoring) to achieve reliable, deadlock-free operation. Finally, we highlight future trends, including upcoming 800 Gbps Ethernet technologies, enhancements for AI networking, and the role of emerging DPUs in evolving RoCEv2-enabled fabrics. The insights and guidelines in this paper can inform both academic research and practical implementation of RoCEv2 in modern high-performance networks.
Keywords
RDMA; RoCEv2; Lossless Ethernet; High-Performance Computing; InfiniBand; iWARP; Data Center Networking; AI Training; NVMe-oF; DPU (Data Processing Unit)
Introduction
Remote Direct Memory Access (RDMA) technology provides low-latency, high-bandwidth network communication by allowing one computer to directly read/write the memory of another, bypassing the kernel and CPU involvement. Unlike traditional TCP/IP sockets that incur significant CPU overhead and copy latency, RDMA offloads data transfer to specialized network adapters, achieving lower end-to-end latency and higher throughput. RDMA has been widely used in high-performance computing (HPC) and storage networks (e.g. InfiniBand fabrics) due to these performance advantages. However, InfiniBand requires a dedicated network infrastructure. To bring RDMA benefits to ubiquitous Ethernet networks, the InfiniBand Trade Association introduced RDMA over Converged Ethernet (RoCE).
RoCE allows RDMA traffic to run over Ethernet links while preserving the zero-copy, low-latency characteristics of InfiniBand. The first version, RoCE v1, operated at the Ethernet link layer (Layer 2) and was limited to a single Ethernet broadcast domain (non-routable). RoCEv2, the focus of this paper, was subsequently developed to enable routability at Layer 3. RoCEv2 encapsulates InfiniBand transport packets over UDP/IP, using a reserved UDP destination port (4791). This allows RoCEv2 frames to be forwarded by IP routers, expanding RDMA connectivity across subnets and large topologies. By using standard Ethernet and IP, RoCEv2 aims to combine InfiniBand-like performance with the flexibility and cost-effectiveness of Ethernet infrastructure.
Significance: RoCEv2 has become increasingly important in data center and cloud environments that demand both high performance and scalability. Applications such as distributed machine learning, disaggregated storage (NVMe-oF), financial trading, and hyper-converged infrastructure all benefit from the ultra-low latency and high throughput that RoCEv2 can provide. Major cloud providers and enterprises have adopted RoCEv2 to interconnect servers and GPU nodes, leveraging existing Ethernet networks for RDMA while avoiding the cost and complexity of deploying InfiniBand clusters. This paper provides a comprehensive overview and analysis of RoCEv2, including its technical architecture, recent developments, use cases, and best practices for deployment. We also compare RoCEv2 with alternative RDMA solutions (InfiniBand and iWARP) to elucidate performance trade-offs and suitability for various scenarios. The remainder of this paper is organized as follows: Section II presents a detailed technical analysis of RoCEv2’s protocol and requirements; Section III reviews recent developments and industry adoption; Section IV discusses case studies of RoCEv2 in real-world systems; Section V offers a comparative analysis against InfiniBand and iWARP; Section VI outlines best practices for deploying RoCEv2; Section VII looks at future outlook and emerging trends; and finally Section VIII concludes with references.
Technical Analysis
Packet Structure and Routing Capabilities
RoCEv2 operates by encapsulating InfiniBand transport packets into UDP/IP packets, making RDMA possible over routable Ethernet networks. In essence, the RoCEv2 packet format includes an Ethernet header, an IP header (IPv4 or IPv6), a UDP header, and then the InfiniBand RDMA transport header and payload. The UDP source and destination ports identify the RDMA traffic (port 4791 is reserved for RoCEv2). By using UDP, RoCEv2 forgoes the reliability and ordering guarantees of TCP; instead, it relies on the InfiniBand transport layer (e.g. Reliable Connections, RC) and link-level flow control to ensure reliable, ordered delivery. Because RoCEv2 packets are standard IP datagrams, they can traverse Layer 3 routers and IP fabrics just like ordinary UDP traffic, earning RoCEv2 the name “Routable RoCE” (RRoCE). This routability is a key improvement over RoCE v1, enabling RDMA to scale beyond a single layer-2 domain.
Despite running on an unreliable transport (UDP), RoCEv2 is designed to preserve packet ordering for packets belonging to the same RDMA session. The RoCEv2 specification mandates that packets with the same source QP (Queue Pair) and destination should not be reordered in transit. In practice, this means that within a given RDMA flow, the network should avoid reordering (a reasonable assumption on typical Ethernet fabrics using consistent hashing or single-flow routes). If an out-of-order or dropped packet does occur, higher-level IB transport mechanisms or upper-layer protocols may handle retries, but timely delivery is critical to RDMA performance. To mitigate packet loss and reordering, RoCEv2 deployments typically leverage a combination of network features discussed next.
Lossless Ethernet: PFC, ECN, and QoS Mechanisms
Because RDMA (especially in Reliable Connection mode) expects a virtually lossless fabric, RoCEv2 works best on Ethernet networks that are configured to minimize packet loss. Priority Flow Control (PFC) and Explicit Congestion Notification (ECN) are two key technologies used to achieve a lossless (or effectively lossless) Ethernet environment for RoCEv2 traffic.
- Priority Flow Control (PFC): PFC is an IEEE 802.1Qbb standard that provides pause flow control on a per-priority basis. Network switches and adapters use PFC to pause RDMA traffic classes before their buffers overflow, preventing packet drops during congestion
- Explicit Congestion Notification (ECN) and RoCE Congestion Control: PFC alone handles instantaneous buffer pressure, but to manage sustained congestion, RoCEv2 employs congestion control based on ECN. Switches are configured to mark the IP header ECN bits on RDMA packets when queue lengths exceed a threshold, indicating congestion. The receiving NIC, upon detecting ECN-marked packets, sends a special Congestion Notification Packet (CNP) back to the sender’s NIC
- Quality of Service (QoS): In a converged network carrying both RDMA and regular traffic, QoS and traffic class separation are critical
In summary, achieving a lossless Ethernet fabric for RoCEv2 involves enabling PFC on the RDMA priority, configuring ECN on all switches and routers in the path, and using QoS policies to segregate and protect RDMA traffic. These measures allow RoCEv2 to run without packet loss or prolonged congestion, which is essential for its performance to approach that of native InfiniBand.
Layer 3 Scaling Considerations
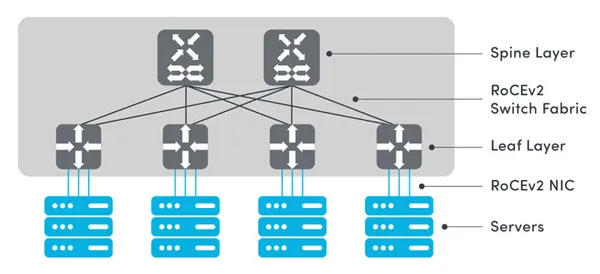
One of RoCEv2’s chief advantages is its ability to scale RDMA over Layer 3, leveraging IP routing to interconnect far larger clusters than RoCE v1 could support. In large-scale data centers with multi-tier leaf-spine topologies, RoCEv2 can span thousands of nodes by routing over the spine layer, whereas RoCE v1 (limited to one subnet/VLAN) could not. Layer 3 scaling with RoCEv2 does introduce new considerations:
- Routability and IP Configuration: Each RoCEv2 node requires IP addresses and proper routing. RoCEv2 traffic can be load-balanced using equal-cost multi-path (ECMP) routing across the fabric, similar to other UDP traffic. However, ECMP hashing must ensure that all packets of an RDMA flow follow the same path (to avoid reordering). This typically means the hash includes the 5-tuple (source/dest IP, source/dest UDP port, etc.), which keeps a given RDMA connection on a single path. Routing protocols (OSPF, BGP in data centers) handle reachability, and RoCEv2 imposes no special requirements on L3 aside from supporting ECN marking. The use of standard IP also allows interconnecting RDMA clusters over layer-3 boundaries (e.g., between pods or buildings), though in practice most RoCEv2 deployments remain within a single data center.
- Lossless Behavior Across L3 Boundaries: PFC is an Ethernet link-layer mechanism and does not extend end-to-end across routed hops. In an IP fabric, each link between routers/switches still needs to be lossless for RDMA class traffic, but a PFC pause on one link will not directly pause traffic beyond the next hop. This makes proper end-to-end congestion control (ECN/CNP as described above) even more important in multi-hop L3 networks
- Scalability of Connection State: Large-scale RDMA usage means many Queue Pairs (QPs) and associated connection state. InfiniBand stacks and RNICs (RDMA NICs) are designed to handle a high number of QPs, but there are practical limits. Unlike iWARP (RDMA over TCP) which must maintain a full TCP connection (with its buffers and control blocks) per RDMA session, RoCEv2’s use of UD/IB transport is more lightweight in terms of connection state, improving scalability
- Traffic Isolation and Reliability Domains: In scaled-out RoCEv2 networks, operators often isolate the RDMA fabric for performance and reliability. For example, Meta’s AI clusters use a dedicated “backend” network solely for RoCEv2 traffic between GPUs, separate from the general-purpose data center network
In practice, RoCEv2 has demonstrated the ability to scale to thousands of nodes in a cluster. Meta’s recent distributed AI training clusters, for instance, interconnect on the order of 2000–4000 GPUs using RoCEv2 fabrics and have evolved to data-center-scale deployments by leveraging L3 routing and careful topology-aware scheduling. As network size grows, so does the importance of robust congestion management — large-scale tests have shown RoCEv2 can remain stable without significant packet loss when PFC and ECN are properly implemented, even under all-to-all traffic patterns common in AI workloads. Nonetheless, operators must be vigilant for issues like PFC deadlock and need to use features such as PFC watchdogs or dynamic routing to alleviate hotspots in ultra-large networks.
RDMA Performance Benchmarks (RoCEv2)
RoCEv2 is capable of delivering performance very close to InfiniBand in terms of latency and throughput, provided the network is lossless and tuned. Several benchmarks and studies illustrate RoCEv2’s performance:
- Latency: Modern RoCEv2 NICs (such as NVIDIA Mellanox ConnectX series) can achieve end-to-end latencies on the order of 1–5 microseconds within a data center, depending on packet size and link speed
- Throughput: RoCEv2 can deliver full line-rate bandwidth on high-speed Ethernet links. Because it bypasses the kernel and avoids TCP overhead, RoCEv2 can saturate a 100 Gbps link with large message RDMA transfers, whereas standard TCP might struggle with CPU overhead at such speeds. Benchmarks have shown RoCE achieving near 40 GbE line rate on older hardware and scaling proportionally on 100 GbE and 200 GbE networks
- CPU Overhead: One of the motivations for RDMA is to reduce CPU usage. RoCEv2’s kernel bypass and RDMA offloads dramatically cut CPU overhead per byte transferred compared to TCP/IP. Measurements indicate that RoCE can not only lower latency but also free up CPU cycles – which is advantageous for compute-intensive workloads that cannot spare cores for networking
- Comparative Performance: Compared to iWARP (RDMA over TCP), RoCEv2 generally exhibits better latency and throughput, especially at scale. A study found that earlier-generation iWARP adapters had ~3× higher latency and 4× lower throughput than RoCE under heavy loads
In summary, RoCEv2 brings RDMA performance to Ethernet, achieving very low latency and high throughput. Benchmarks in both lab and production (cloud) environments show that with proper configuration, RoCEv2 can approach the performance of specialized HPC interconnects, enabling new levels of application performance on standard data center networks.
Recent Developments and Industry Adoption
RoCEv2 has rapidly evolved in both the hardware that supports it and the breadth of its adoption across the industry. This section highlights recent advancements and how various sectors are leveraging RoCEv2:
- Advanced RoCEv2-Capable Hardware: Networking vendors have continually improved RDMA-capable Ethernet NICs and switches. For example, NVIDIA (Mellanox) ConnectX series NICs support RoCEv2 at 100 Gbps and 200 Gbps speeds, with the latest ConnectX-7 and -8 aiming at 400 Gbps and beyond. Switch silicon from multiple vendors (Broadcom, Cisco, Juniper) now include features to better support RoCEv2 traffic, such as deeper buffers with intelligent packet scheduling, faster congestion feedback (ECN marking optimizations), and even support for dynamic routing to avoid congestion hotspots. A notable development is the emergence of Data Processing Units (DPUs) or “SmartNICs”, like NVIDIA’s BlueField family, which integrate Arm cores and RDMA offload engines on the NIC. The NVIDIA BlueField-3 DPU delivers up to 400 Gb/s RoCEv2 throughput and hardware-accelerated congestion control, and the forthcoming BlueField-4 is expected to support 800 Gb/s networking
- Software and Ecosystem Support: On the software side, RoCEv2 has become widely supported in operating systems and frameworks. Linux distributions include RoCEv2 support in the inbox RDMA subsystem (since kernel 4.5)
- Hyperscaler and Cloud Adoption: Many hyperscale cloud providers and internet companies have adopted RoCEv2 to accelerate demanding workloads. Meta (Facebook) is a prime example – they chose RoCEv2 as the fabric for their AI research clusters, interconnecting thousands of GPUs for large-scale training
- AI/ML Workloads Driving Innovation: The explosion of AI and machine learning workloads – particularly distributed training of deep neural networks – has been a significant driver for RoCEv2 adoption and innovation. Training large models requires scaling to thousands of GPUs or accelerators, with massive volumes of gradient data exchanged between nodes. RoCEv2 provides the high bandwidth and low latency needed for techniques like all-reduce and parameter server synchronization to scale efficiently. As AI cluster sizes grow, network designers have had to refine RoCEv2 fabrics: for example, implementing topology-aware scheduling (assigning jobs to GPUs that are network-nearby to reduce congestion)
In summary, RoCEv2 has moved from an emerging technology to a mainstream solution for high-performance networking. Robust hardware and software support, coupled with adoption by leading cloud providers and enterprises, indicate a strong ecosystem. The protocol continues to evolve to meet new challenges (higher speeds, larger scale, new workloads), ensuring that RoCEv2 remains relevant for the next generation of data center networking.
Case Studies
To ground the discussion in real-world scenarios, we examine several case studies where RoCEv2 is deployed to solve high-performance networking challenges:
Case Study 1: Meta AI Training Clusters
Meta (Facebook) operates some of the world’s largest AI training clusters for tasks like recommendation systems and large language model training. As detailed by Meta’s engineers, they implemented a dedicated RoCEv2-based network fabric to connect tens of thousands of GPUs across many racks. Each training cluster consists of thousands of GPU servers linked via a non-blocking RoCEv2 fabric – a specialized “backend” network separate from Meta’s general data center network. This backend uses high-speed Ethernet switches configured for lossless RDMA (via PFC) and supports adaptive routing for load balancing. RoCEv2 was chosen after evaluation because it offers InfiniBand-like latency and throughput but on Ethernet hardware that Meta can integrate with their existing infrastructure.
One notable aspect is Meta’s success in scaling RoCEv2. They have reported deploying multiple RDMA clusters, each with on the order of 2048 to 4096 GPUs, and achieving reliable performance at that scale. The network provides low tail latency for collective communication (which is critical as synchronized steps in training are only as fast as the slowest message). Meta’s design uses PFC for flow control and, interestingly, they found that with their workload patterns (dominated by synchronized GPU collectives), they did not observe persistent congestion requiring advanced congestion control beyond PFC. This suggests that a well-provisioned RoCEv2 fabric, dedicated to a single application domain, can be operated with relatively simple flow control (PFC only) and still avoid heavy congestion. The Meta case study demonstrates RoCEv2’s capability to enable AI supercomputer-scale networks, delivering the bandwidth and latency needed for multi-week training runs of models with hundreds of billions of parameters. It has effectively proven that Ethernet with RoCEv2 can be a viable alternative to InfiniBand even at the highest end of AI computing, given careful network engineering.
Case Study 2: Azure Stack HCI in Enterprise Data Centers
Microsoft Azure Stack HCI is a hybrid cloud solution that enables enterprises to run Azure services on-premises with a cluster of Windows servers. A key aspect of Azure Stack HCI is software-defined storage and networking between the cluster nodes. Microsoft highly recommends RDMA networking for Azure Stack HCI clusters to improve performance of east-west traffic (such as live migration, storage replication via SMB Direct, and CSV traffic). In this context, RDMA can be provided by either iWARP or RoCEv2, as supported by Windows Server. Microsoft’s documentation notes that RoCEv2 requires a lossless DCB configuration on the network fabric, whereas iWARP can function over standard IP networks without special switch configuration. Due to the complexity of setting up PFC/DCB across switches, Microsoft’s default guidance often leaned toward iWARP (which some OEM NICs like Chelsio or QLogic provide) to reduce misconfiguration issues. However, many Azure Stack HCI implementations opt for RoCEv2, especially when using modern NICs from vendors like Mellanox (NVIDIA) or Broadcom that support RoCEv2 well.
In practice, Azure Stack HCI deployments with RoCEv2 have achieved notable performance gains. For example, a 4-node HCI cluster with all-NVMe storage can use 25 Gbps RoCEv2 connectivity to deliver extremely fast Storage Spaces Direct throughput and low latency for VM disk access, surpassing what is possible with TCP/IP alone. Microsoft has observed roughly 15% average improvement in storage performance by enabling RDMA in HCI clusters. In one Azure Stack HCI case, a customer using RoCEv2 NICs and switches saw not only higher IOPS but also reduced CPU consumption on storage tasks, because the CPU bypass enabled more efficient data movement. The Azure Stack HCI case study highlights RoCEv2’s value in enterprise environments: even outside of HPC, RDMA can significantly accelerate distributed storage and virtualization workloads. The key lesson is that careful network setup (ensuring all switches and NICs have matching PFC, ETS, and ECN settings) is required for RoCEv2 to function optimally. Once configured, RoCEv2 provides a robust high-performance backbone for hyper-converged infrastructure, effectively bringing cloud-grade performance to on-premises deployments.
Case Study 3: Oracle Cloud – RDMA for Low-Latency Trading Systems
Financial trading systems demand extremely low latency for message exchange (orders, market data) – traditionally achieved with on-premises InfiniBand or specialized hardware. Oracle Cloud Infrastructure (OCI) set out to prove that cloud infrastructure using RoCEv2 can meet these stringent requirements. Oracle’s HPC offerings include an RDMA cluster network (based on RoCEv2 over 100 Gb Ethernet) that customers can use for tightly-coupled workloads. In collaboration with capital markets experts, a foreign exchange trading engine was tested on OCI’s RoCEv2 network. The goal was to see if matching engine and order book communication could be kept under sub-millisecond latency in the cloud. The results were impressive: By replacing the default TCP-based networking with RoCEv2, the team achieved median latencies in the single-digit microsecond range for the trade execution flow. Specifically, at 10,000 orders per second, the trading system saw a minimum latency of ~6.6 µs and 99th percentile of ~12.5 µs, whereas using TCP/IP was giving hundreds of microseconds. Even as they scaled up message rates to 500,000 ops/sec, RoCEv2 kept the 99th percentile latency around 11 µs (with some higher outliers under stress).
This case study illustrates that RoCEv2 can deliver deterministically low latency in a multi-tenant cloud environment, essentially on par with what a private InfiniBand network might achieve. Oracle’s use of RoCEv2 was deliberate – they evaluated both iWARP and RoCE and “chose RoCE for its performance and wider adoption” in the industry. The OCI RDMA network uses features like cut-through switching and CPU isolation (bare-metal instances) to minimize jitter. It demonstrates that cloud providers can support specialized workloads like HFT (High-Frequency Trading) by leveraging RoCEv2 to provide HPC-grade performance. For financial firms, this opens the door to cloud adoption without sacrificing the microsecond-level responsiveness that their algorithms require.
Case Study 4: NVMe-oF in Enterprise Storage Networks
Enterprise storage is increasingly adopting disaggregated architectures, where servers access remote flash storage over a network using NVMe-over-Fabrics (NVMe-oF). RoCEv2 has become a popular fabric option for NVMe-oF (specifically NVMe/RDMA) in modern storage arrays and storage networks. In a typical deployment, an all-flash storage array is equipped with RoCEv2-capable NICs, and storage initiators (clients) use RoCEv2 NICs to send NVMe commands encapsulated in RDMA to the array. This setup provides direct, high-speed access to remote NVMe devices with minimal latency overhead.
For example, Pure Storage and Arista published a technical proof-of-concept for NVMe-oF using RoCEv2 in a leaf-spine data center network, demonstrating that NVMe storage traffic could be carried over a routed Ethernet fabric without performance loss. They showed that with a properly configured network (all switches enabled PFC on the RoCE traffic class and ECN for congestion), the remote NVMe volumes performed almost indistinguishably from direct-attached NVMe in terms of IOPS and latency. The network testbed ran at 100 GbE and used RoCEv2 to connect initiators to targets. A key takeaway was that lossless Ethernet is mandatory for NVMe/RoCE – even a small amount of packet loss or jitter can significantly degrade I/O throughput and tail latency. Many storage vendors have embraced RoCEv2 for their NVMe-oF solutions because it allows them to use standard Ethernet switching hardware while delivering microsecond-level response times. Enterprises deploying NVMe-oF over RoCE have reported latency on the order of 100 µs or less for remote flash access, which is a huge improvement over iSCSI or TCP-based NAS protocols (which often incur 500 µs to milliseconds). RoCEv2 thus enables the vision of a true storage area network over Ethernet that performs like local storage – combining the flexibility of networked storage with the performance of RDMA.
In summary, these case studies (spanning AI superclusters, hyper-converged enterprise clusters, cloud HPC/trading, and storage networks) collectively demonstrate the versatility and impact of RoCEv2. Across different domains, RoCEv2 consistently provides significant latency and throughput benefits, unlocking new capabilities (like training very large AI models, or trading at ultra-low latency in the cloud) that would be hard to achieve with conventional networking. Each scenario also underscores important deployment considerations, from the need for careful network configuration (PFC/ECN) to the validation of RoCEv2’s stability at scale.
Comparative Analysis: RoCEv2 vs. InfiniBand vs. iWARP
RoCEv2 is one of three primary technologies for RDMA networking, the other two being InfiniBand (IB) and iWARP. Each has its own strengths and trade-offs in terms of performance, cost, and infrastructure requirements. We compare them along key dimensions:
- Performance (Latency and Bandwidth): InfiniBand is often regarded as the gold standard for low latency. It achieves extremely low transport latencies (as low as 1–2 µs end-to-end) thanks to a lightweight protocol and switch hardware optimized for HPC
- Reliability and Congestion Handling: InfiniBand provides reliable delivery at the link layer using credit-based flow control – a sending node only transmits when it has credits indicating buffer space at the receiver, ensuring no packet loss in the fabric
- Scalability: InfiniBand networks can scale to large cluster sizes (tens of thousands of nodes) with support from features like partition keys (for isolation) and efficient multicast and collective offloads. Commercial IB deployments have reached cluster sizes of 10k+ nodes while maintaining performance
- Ease of Deployment: This is a significant differentiator. InfiniBand requires a completely separate network stack – specialized IB switches, adapters, and a subnet manager to configure the fabric. This means higher cost and complexity, but vendors often provide management tools (e.g., Mellanox UFM) that automate fabric setup
- Vendor Support and Ecosystem: InfiniBand is supported by a few vendors (primarily Mellanox/NVIDIA, and Intel’s Omnipath was a fork of IB technology). RoCEv2 is widely supported by many Ethernet NIC vendors – NVIDIA (Mellanox) and Broadcom Emulex are strong proponents, and Intel now supports RoCEv2 on their Ethernet NICs as well
- Cost Considerations: InfiniBand hardware tends to be more expensive and often proprietary. IB adapters and switches are sold by fewer vendors, and interoperability between vendors can be limited (though IB is standardized by IBTA). Ethernet (and thus RoCEv2) benefits from economies of scale – data center Ethernet switches and NICs are produced in high volume by many companies, generally making them cheaper per port/Gb. Additionally, using RoCEv2 means a single network for both RDMA traffic and regular Ethernet traffic, potentially simplifying infrastructure. InfiniBand usually ends up as a second network dedicated for cluster communications, adding to infrastructure cost. iWARP can use cheap Ethernet hardware too, but the NICs supporting iWARP specifically (e.g. specialized adapters) might not be as cost-efficient or high-performance. Overall, RoCEv2 often hits a sweet spot: much of IB’s performance with Ethernet’s cost profile and flexibility
In summary, InfiniBand vs RoCEv2: InfiniBand offers slightly better latency and a more turnkey lossless solution, but at higher cost and with a separate infrastructure. RoCEv2 gives comparable performance in most cases, runs on standard gear (lower cost), but requires careful setup to achieve losslessness. Many view RoCEv2 as “InfiniBand over Ethernet” – combining IB’s RDMA semantics with Ethernet’s ubiquity. RoCEv2 vs iWARP: RoCEv2 generally outperforms iWARP in latency and throughput, especially for HPC or AI workloads that are sensitive to microseconds. iWARP’s main advantage is ease of deployment on legacy networks and guaranteed reliability via TCP, but that comes with higher latency and complexity in the NIC implementation. In large modern data centers where administrators can configure DCB, RoCEv2 is usually preferred over iWARP.
It is worth noting that as of the mid-2020s, the gap between InfiniBand and RoCEv2 is narrowing. Organizations like Meta have found RoCEv2 “as good as InfiniBand” for their purposes, and many new large deployments choose RoCEv2 for its cost and flexibility advantages. Meanwhile, iWARP has seen declining adoption as RoCEv2 and InfiniBand cover most needs. Therefore, the industry consensus is shaping up around InfiniBand for specialized closed HPC systems and RoCEv2 for mainstream data center RDMA, with iWARP largely overtaken by RoCEv2’s success.
Best Practices for RoCEv2 Deployment
Deploying RoCEv2 in a production environment requires careful planning and configuration to ensure stable, high-performance operation. The following best practices serve as a step-by-step guide for implementing RoCEv2 networks:
- Use RoCEv2-Capable Hardware and Firmware: Ensure all servers have RoCEv2-capable NICs (RDMA NICs) and that switches support Data Center Bridging features. Update NIC firmware and drivers to the latest recommended versions for RDMA. For instance, use NICs from vendors known for RoCE support (NVIDIA Mellanox ConnectX series, Broadcom NetXtreme/Ethernet with RoCE support, etc.) and verify that RoCEv2 is enabled (in some NIC firmware, you may need to enable RDMA or set the protocol to RoCEv2 specifically).
- Network Design – Dedicated RDMA VLAN or Network: If possible, segregate RoCEv2 traffic onto its own VLAN or even a physical network. Many deployments use a dedicated VLAN for RDMA to separate it from regular traffic and apply DCB settings on that VLAN. In high-end scenarios (like GPU clusters), consider a fully separate fabric for RoCEv2 to reduce interference
- Enable Priority Flow Control (PFC): Configure switches and host NICs to enable PFC on the priority class that will carry RDMA traffic. Choose an appropriate priority (e.g., Priority 3 or 4) to dedicate to RoCEv2. On switches, enable PFC globally and on each interface for that priority. On hosts, set the NIC’s DCB configuration to tag outgoing RDMA packets with the chosen priority (this may be done via OS tooling like lldptool or NIC utilities). Verify end-to-end that PFC is functioning: most switches provide counters for PFC pause frames sent/received – these should increment if congestion occurs, indicating PFC is pausing traffic to prevent drops. Important: Make sure only the RDMA traffic class has PFC enabled. Do not indiscriminately enable PFC on all traffic, as that increases the risk of pause propagation issues
- Configure Explicit Congestion Notification (ECN): Enable ECN marking on all switches for the RDMA priority class. Typically, this involves setting a queue threshold for ECN – when the queue depth exceeds X (e.g., some number of bytes or packets), the switch will mark the ECN bit in packets instead of dropping them. Use recommended ECN thresholds from your switch vendor or based on guidance (for example, tail-drop might occur at 100% queue depth, set ECN mark at 5–10% queue depth to signal early). On the hosts, ensure that the RoCEv2 NIC’s congestion control algorithm (DCQCN) is enabled and configured (most modern RNICs have this on by default). This allows the NIC to respond to CNP messages by rate-limiting. Some OS drivers might expose parameters for CC (like reaction time, rate decrease factor); using default values is fine unless tuning is needed. ECN configuration is vital for large-scale RoCE to avoid excessive reliance on PFC – it provides a more graceful congestion management
- Quality of Service and Traffic Separation: Map RDMA traffic to a specific hardware queue and priority. In Windows, this is done by setting up a DCB policy where SMB Direct/RDMA traffic is tagged with a priority (via the host NIC QoS settings). In Linux, one can use tc (traffic control) or vendor tools to ensure all RoCEv2 traffic (e.g., by UDP port 4791) is placed in the lossless queue. Allocate sufficient bandwidth to the RDMA class using ETS if the network is converged. For example, if you have 50% storage traffic (RDMA) and 50% normal traffic, allocate at least 50% of link bandwidth to the RDMA class. This prevents starvation and ensures predictable performance
- End-to-End MTU Consistency: Configure jumbo frames for RDMA if supported – typically 9000 bytes MTU. All switches and NICs in the path must have the same MTU. A mismatched MTU will cause subtle issues (like packets getting dropped or segmented). Jumbo frames reduce CPU interrupts and improve efficiency for large transfers (though for small RDMA messages it doesn’t change latency). Ensure the IP MTU (and underlying Ethernet MTU) is set to the desired value on every interface in the RDMA VLAN.
- Test the RDMA Network: Before putting real workload, use testing tools to verify RDMA functionality and performance. Utilities like ib_write_bw and ib_read_lat (from perftest package) or qperf can measure one-way and round-trip latency and throughput between two RDMA endpoints. Run these tests to ensure you get expected microsecond-level latencies and high throughput. If the results show unexpectedly high latency or drops (throughput not scaling), that indicates a misconfiguration (common issues: PFC not actually enabled, or ECN marking misbehaving). Microsoft’s Validate-DCB tool (for Windows) is also useful to automatically check that each node and switch has consistent DCB settings
- Monitoring and Tuning: Once live, continuously monitor the network for signs of congestion or problems. Key metrics to watch: PFC pause frame counters on switches (if they increment frequently, you have frequent congestion requiring pause – consider adjusting ECN threshold or adding more bandwidth/capacity); ECN marked packet counters (if zero, maybe ECN isn’t working; if very high, there’s frequent moderate congestion); RDMA QP error counters (e.g., retransmission events, which could indicate packet loss). Also monitor for any switch buffer discards on RDMA queues – any drop can severely impact performance. If drops are detected, investigate cause (e.g., perhaps a mis-routed flow or a non-RDMA packet in the RDMA queue causing interference). It’s good practice to implement a PFC watchdog on switches that supports it – this will detect if a port is stuck in a paused state and automatically release it to avoid deadlock
- Separate Traffic or Enable Selective Delta for Mixed Workloads: If combining RDMA and regular traffic on the same network, ensure that non-RDMA traffic cannot clog the RDMA queues. This typically is done via QoS as mentioned. Additionally, avoid sending RDMA traffic into devices that are not configured for it. For example, if one link in the chain doesn’t have PFC/ECN (like a firewall or older switch), that link can drop RDMA packets and break performance. Thus, keep the RDMA path homogenous and consider isolating it from devices or services (like IPS appliances) that might not understand PFC.
- Documentation and Vendor Guidance: Follow vendor-specific RDMA configuration guides. Many switch vendors (Cisco, Juniper, Arista) publish best practice guides for RoCEv2 networks, which include recommended buffer settings, ECN values, and example configurations
- Staging and Scalability Testing: If deploying RoCEv2 at scale (dozens or hundreds of nodes), test incrementally. Start with a smaller fabric (a few nodes, a single switch) to validate the config, then scale out. When adding more switches (multi-hop), test again as the dynamics can change (PFC interacts differently when multiple hops, and ECN marking becomes more crucial). Use tools or scripts to simulate heavy RDMA traffic patterns (like many simultaneous connections) to ensure the network can handle the load. Scalability testing can reveal issues like insufficient switch buffer for certain traffic bursts or the need to tune CNP timers on NICs for larger diameters.
By following these best practices, administrators can deploy RoCEv2 in a stable and optimized manner. The key themes are ensuring losslessness, consistent QoS, and active monitoring. A well-tuned RoCEv2 network will deliver excellent performance, but if misconfigured, it can degrade or even deadlock, so diligence in setup and maintenance is essential. When in doubt, refer to proven reference architectures (from cloud providers or storage vendors) and leverage the RDMA community forums for guidance on complex issues. With the right approach, RoCEv2 can run production workloads reliably, as evidenced by the case studies earlier.
Future Outlook
As we look ahead, several trends and upcoming advancements are poised to influence the landscape of RoCEv2 and high-performance networking in general:
- Scaling to 800G Ethernet and Beyond: Network bandwidth demands continue to grow, driven by AI data, distributed compute, and high-resolution media. The Ethernet industry is on the cusp of 800 Gbps (800G) and even 1.6 Tbps link speeds. In 2024, vendors have announced NICs and switches that support 800G – for example, NVIDIA’s roadmap includes the BlueField-4 DPU with dual 400G ports (800G total)
- AI Fabric Enhancements: AI networks will continue to be a major driving force for RDMA innovation. Future AI clusters (for training trillion-parameter models, for example) might consist of tens of thousands of accelerators, necessitating even more scalable network designs. We anticipate techniques from InfiniBand making their way into Ethernet-based RoCE fabrics: for instance, adaptive routing at the packet level could be implemented in Ethernet switches via emerging protocols like MPLS-based load balancing or new extensions to ECMP, to better avoid congestion in real time (InfiniBand already does per-packet adaptive routing to improve load distribution
- DPU and SmartNIC Evolution: Data Processing Units are emerging as a key component in modern servers, and their role will expand in RDMA networking. Current DPUs like BlueField-3 already handle RDMA traffic steering, virtualization (SR-IOV), and even TCP/IP offload, but future iterations are likely to implement more sophisticated RDMA management in hardware. For example, a DPU could dynamically adjust congestion control parameters on a per-flow basis using its on-board processors, or it could isolate tenant RDMA traffic in a cloud environment to prevent one tenant from affecting another. In multi-tenant public clouds, one concern with RDMA is ensuring that one VM’s misbehaving RDMA session (e.g., not responding to CNP, or causing PFC storm) doesn’t impact others. DPUs can enforce fairness and provide isolation at the NIC level, which will be crucial as RoCEv2 sees broader cloud adoption. We might also see RoCEv2 virtualization improvements – technologies to allow VMs and containers to safely share an RDMA NIC (beyond basic SR-IOV). NVIDIA’s Virtual Private Fabric concept, for instance, could allow each tenant to feel like they have their own lossless RDMA network while the DPU handles traffic policing between them. In summary, DPUs will likely become the “traffic cops” for RoCEv2, enabling larger, safer deployments especially in cloud and edge computing scenarios. By offloading not just data movement but control logic, DPUs could reduce CPU usage further and enable new RDMA use cases (like secure RDMA across data centers, or RDMA for memory pooling with CXL in the future).
- Enhanced Reliability and Routing for RoCEv2: Another trend is improving RoCEv2’s robustness for wider area use. Currently, RoCEv2 is generally confined to LAN environments because it assumes a relatively controlled network. But as distributed computing spans multiple data centers (for disaster recovery or multi-cloud AI training, for example), there is interest in extending RDMA across longer distances. Protocol extensions or complementary technologies might emerge – for instance, using Resilient RoCE or hybrid approaches where RoCEv2 can fail over to a TCP-based channel if needed (some vendors have talked about “Rocky” which is RoCE over TCP as a backup). Also, multipath RDMA is a research area: using multiple network paths simultaneously for one RDMA connection to improve resilience and throughput. This would require changes to how queue pairs are handled or having some aggregation layer above RDMA.
- Convergence with InfiniBand: We may also see a convergence or at least cross-pollination between InfiniBand and RoCE. The InfiniBand Trade Association continues to maintain both IB and RoCE specs. As Ethernet technology improves, the justification for separate IB networks might diminish for many (except the most latency-sensitive HPC). It’s possible future InfiniBand versions could even incorporate Ethernet PHY layers or vice versa (Ethernet adopting more IB techniques) – essentially blurring the lines. Already, RoCEv2 carries the IB transport protocol over Ethernet; we might see unified management or gateway devices that seamlessly translate between RoCE and IB networks, giving institutions the option to mix network types. For example, a cluster could use RoCEv2 within racks and IB between racks, with gateways doing the conversion. While speculative, the end goal for the industry is to maximize performance and compatibility. If RoCEv2 continues to prove itself, more HPC sites might switch to Ethernet, and InfiniBand might retreat to niche ultra-low-latency corners, or both could merge in some form.
- New RDMA Applications: Finally, as RoCEv2 becomes common, we expect new applications to leverage it. One area is in persistent memory and memory pooling – the CXL (Compute Express Link) standard allows memory to be shared/disaggregated within a rack; combining CXL with RoCEv2 could enable memory access over network with RDMA semantics. Another area is 5G telecom backhaul and edge computing: telco infrastructure is starting to use RDMA (for example, in 5G NFVi, to meet latency for DU/CU connections). RoCEv2 could play a role in those deployments, especially since they use Ethernet natively (unlike InfiniBand). Also, database systems and distributed SQL engines may increasingly use RDMA for internode communication (some already do, like Oracle RAC uses RoCE). As these applications appear, standards might adapt – for instance, improvements in atomic operations over RoCE (supporting more of InfiniBand’s atomic verbs over Ethernet) would benefit distributed databases that rely on locks or atomic writes.
In conclusion, the future of RoCEv2 looks promising and dynamic. With the trajectory of network speeds (800G), the demands of AI/ML, and the rise of DPUs, RoCEv2 will likely evolve but remain a central technology for high-performance networking. It represents a merging of two worlds – the RDMA performance world and the Ethernet connectivity world – a merger that will deepen as both technologies progress. RoCEv2’s ability to deliver HPC-class performance on standard networks makes it a linchpin for future data center architectures, potentially serving as the unified fabric for compute, storage, and AI. Continued collaboration between industry consortia (IBTA, IEEE) and cloud operators will help address current limitations (congestion issues, config complexity) and ensure that RoCEv2 scales in reliability and usability. The trends indicate that tomorrow’s networks will be even faster, smarter, and more programmable – and RoCEv2 is well-positioned to ride that wave, enabling applications we can barely imagine today to communicate at memory-like speeds over vast distances.
References
- Wikipedia: “RDMA over Converged Ethernet.” Wikipedia, 2023. [Online]. Available: https://en.wikipedia.org/wiki/RDMA_over_Converged_Ethernet (accessed Jan. 10, 2025).
- Meta Engineering Blog: Adi Gangidi, James Hongyi Zeng, “RoCE networks for distributed AI training at scale,” Engineering at Meta, Aug. 2024. [Online]. Available: https://engineering.fb.com/2024/08/05/data-center-engineering/roce-network-distributed-ai-training-at-scale/
- QSFPTEK Tech Blog: Leslie, “Everything You Should Know About RoCE,” QSFPTEK, Jan. 2025. [Online]. Available: https://www.qsfptek.com/qt-news/everything-you-should-know-about-roce.html
- Microsoft Learn (Azure HCI): “Validate an Azure Stack HCI cluster – Validate networking,” Microsoft Docs, 2023. [Online]. Available: https://learn.microsoft.com/en-us/azure/azure-local/deploy/validate
- Dell Technologies (Azure HCI Guide): “iWARP vs RoCE for RDMA,” in Tech Book – Dell Integrated System for Microsoft Azure Stack HCI, Dell, 2022. [Online]. Available: https://infohub.delltechnologies.com/l/tech-book-dell-integrated-system-for-microsoft-azure-stack-hci-1/iwarp-vs-roce-for-rdma-23/
- BJSS/CGI Whitepaper: “Low-Latency Trading over RoCE v2 on Oracle Cloud Infrastructure,” BJSS Blog, 2023. [Online]. Available: https://www.bjss.com/articles/low-latency-trading-over-roce-v2-on-oracle-cloud-infrastructure
- Oracle Cloud Blog: “OCI accelerates HPC, AI, and database using RoCE and NVIDIA…,” Oracle Cloud Infrastructure Blog, 2021. [Online]. Available: https://blogs.oracle.com/cloud-infrastructure/post/oci-accelerates-hpc-ai-db-roce-nvidia-connectx
- Pure Storage & Arista Whitepaper: “Deploying NVMe-oF for Enterprise Leaf-Spine Architecture,” Pure Storage, 2020. [Online]. Available: https://www.purestorage.com/content/dam/pdf/en/white-papers/wp-arista-pure-deploying-nvme-of-enterprise-leaf-spine-architecture.pdf
- FS Community Article: “How to Build Lossless Network with RDMA?,” FS Community, 2022. [Online]. Available: https://community.fs.com/article/how-to-build-lossless-network-with-rdma.html
- NVIDIA Mellanox Whitepaper: “RoCE vs. iWARP Competitive Analysis,” Mellanox Technologies, 2017. [Online]. Available: https://network.nvidia.com/pdf/whitepapers/WP_RoCE_vs_iWARP.pdf
- InfiniBand Trade Association: “RoCE and InfiniBand: Which should I choose?,” InfiniBand Trade Association Blog, 2018. [Online]. Available: https://www.infinibandta.org/roce-and-infiniband-which-should-i-choose/
- StarWind Blog (Azure HCI Networking): Romain Serre, “Design the network for Azure Stack HCI,” Nov. 29, 2022. [Online]. Available: https://www.starwindsoftware.com/blog/design-the-network-for-azure-stack-hci/
- Juniper Networks Blog: Arun Gandhi, “RDMA over Converged Ethernet Version 2 for AI Data Centers,” Juniper The Feed, 2023. [Online]. Available: https://www.juniper.net/us/en/the-feed/topics/ai-and-machine-learning/rdma-over-converged-ethernet-version-2-for-ai-data-centers.html
- NVIDIA BlueField Data Sheet: “NVIDIA BlueField-3 DPU,” NVIDIA, 2022. [Online]. Available: https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/documents/datasheet-bluefield-3.pdf (BlueField-3 specs with 400 Gb/s and RoCE support)
- IBTA RoCEv2 Specification: “InfiniBand Architecture Specification Volume 1, Release 1.3,” Annex 17 (RoCEv2), InfiniBand Trade Association, 2014.